반응형
목표
- 영국의 가장 오래된 뉴스 통신사인 로이터의 '기사내용'이 들어가면 어떤 '주제'인지 카테고리를 예측해보자
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 로이터 뉴스 데이터 임프토
from tensorflow.keras.datasets import reuters
data = reuters.load_data()
data
(X_train, y_train), (X_test,y_test) = data
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
(8982,)
(8982,)
(2246,)
(2246,)# 실제 뉴스 기사의 단어들을 다 숫자로 변경시켜서 저장해둔 데이터
# 현재 로이터 뉴스 기사 데이터셋은 레이블인코딩으로 인코딩을 해준 상태
# 레이블 인코딩 하면서 가장 빈도수가 높은 순위로 숫자가 매겨져 있음
# (1이 가장많이 나온단어, 숫자가 커질수록 빈도수가 적은 단어)
X_train[0]
# 로이터 뉴스기사의 단어들 별로 어떤 숫자로 인코딩 되어 있는지 확인
news_words = reuters.get_word_index()
news_words
- 단어의 빈도수에 따라 딕셔너리 데이터들을 정렬해보자
# 딕셔너리는 순서가 없고 key값으로만 접근이 가능하기 때문에 value값도 같이 활용하기 위해 items 명령을 사용함
# items : 딕셔너리 형태의 key, value값을 튜플로 변경하여 dict_items 자료형태로 만들어주는 명령
news_words.items()
# 딕셔너리를 리스트로 만들려면 번거러운데 이를 줄이면서 정렬이나 반복문에 적용할 수 있는 dict_items 형태로 변환하여 주로 사용함
('sludge', 29043), ('misconduct', 29044),
('satisfies', 19914), ('ticket', 9929), ('purolatr', 29045), ('hassenberg', 19915),
('recreational', 29046), ('clearances', 15818), ('fad', 20552), ('37p', 29048),
('tricentrol', 13466), ('norcem', 29049), ('eventually', 2191), ('norcen', 11873),
('fhlmc', 19916), ('break', 1998), ('suratanakaweekul', 29050), ('furman', 13467),
('owned', 321), ('dickson', 29051), ('divesting', 15819), ('jesus', 29052), ('bread', 5658),
('oxygen', 19917), ('bennedtt', 29053), ('379', 4653), ('378', 6379), ('regionalized', 29054),
('371', 4395), ('370', 2928), ('373', 4929), ('entitled', 2919), ('375', 2301), ('374', 4088),
('377', 4184), ('376', 4396), ('evolve', 22006), ('prawn', 29055), ('thorugh', 29056),
('reformists', 29057), ('ghiringhelli', 15820), ('network', 1669), ('beefing', 29058),
................................................................# value값이 단어의 빈도수 이기 때문에 value 기준으로 정렬시키기
# sorted(정렬할 데이터, key=기준값, reverse=False : 기본값 오름차순 정렬)
sorted(news_words.items(), key=lambda x: x[1])
# lambda : 함수명을 따로 선언하지 않고 간단하게 사용하는 방식(익명함수), 함수를 정의함과 동시에 바로 사용함
# x : x[1] x라는 함수에서 x[1]: value값 기준 / x[0] : key값 기준
# -기존함수-
# def 함수명(매개변수):
# ~~~~~~~~
# return 결과
# -익명함수-
# lambda 매개변수 : 결과
[('the', 1),
('of', 2),
('to', 3),
('in', 4),
('said', 5),
('and', 6),
('a', 7),
('mln', 8),
('3', 9),
('for', 10),
('vs', 11),
('dlrs', 12),
('it', 13),
('reuter', 14),
('000', 15),
('1', 16),
('pct', 17),
('on', 18),
.............# 딕셔너리에서 key값과 value값을 체인지 (key값자리에 value값을 넣고 value자리에 key값을 넣는다)
# -> 숫자로 접근해서 뉴스 기사를 뽑아오기 위해서
word_of_news = {}
# 튜플에 2개의 값이 순서대로 저장돼 있기 때문에 매개변수도 2개로 받아줌
for key, value in news_words.items():
# 비어있는 딕셔너리에 값을 새롭게 넣는데 key값과 value값을 반대로 채워줌 -> 원래는 변수[key값] = value값 으로 대입
# 인코딩된 숫자로 접근해서 문자를 뽑아와서 문장으로 만들기 편하게 하기 위해서
word_of_news[value] = key
print(word_of_news)
print('key값이 1번인 단어:',word_of_news[1])
10996: 'mdbl', 16260: 'fawc', 12089: 'degussa', 8803: 'woods',
13796: 'hanging', 20672: 'localized', 20673: 'sation', 20675: 'chanthaburi',
10997: 'refunding', 8804: 'hermann', 20676: 'passsengers', 20677: 'stipulate',
8352: 'heublein', 20713: 'screaming', 16261: 'tcby', 185: 'four', 1642: 'grains',
20680: 'broiler', 12090: 'wooden', 1220: 'wednesday', 13797: 'highveld', 7593: 'duffour',
20681: '0053', 3914: 'elections', 2563: '270', 3551: '271', 5113: '272', 3552: '273',
3400: '274', 7975: 'rudman', 3401: '276', 3478: '277', 3632: '278', 4309: '279',
9381: 'dormancy', 7247: 'errors', 3086: 'deferred', 20683: 'sptnd', 8805: 'cooking',
20684: 'stratabit', 16262: 'designing', 20685: 'metalurgicos', 13798: 'databank',
20686: '300er', 20687: 'shocks', 7972: 'nawg', 20688: 'tnta', 20689: 'perforations'
...................................................................................
key값이 1번인 단어: the# 출력되는 단어들을 공백을 줘서 연결(문장처럼 만들기)
# 향상된 for문 사용해보기
print(' '.join([word_of_news[key] for key in X_train[0]]))
# .join 예시
print(' '.join(['오늘','점심','메뉴는','뭐먹지?']))
print('~'.join(['오늘','점심','메뉴는','뭐먹지?']))
오늘 점심 메뉴는 뭐먹지?
오늘~점심~메뉴는~뭐먹지?# 향상된 for문 원본 예시 (' '.join[word_of_news[key] for key in X_train[0]])
train_len = []
for key in X_train[0]:
train_len.append(word_of_news[key])
print(' '.join(train_len))
# 향상된 for문과 아래 4줄의 for문과 같은 결과
# 뉴스의 주제 개수를 알아보자 -> 46가지 종류의 주제 존재
np.unique(y_train)
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45])len(X_train[1])
56
len(X_train[0])
87
- CNN도 이미지 데이터를 모두 같은 크기로 변경 시켰듯이 RNN도 뉴스기사의 단어 개수를 같이 맞춰줘야한다 (RNN 신경망의 timesteps는 일정해야 하기 때문에)
- 긴 기사는 잘라내고, 짧은기사는 붙여 넣어줘야함(padding)
# 몇 번을 순환시켜줄지 분석해서 똑같이 맞춰주자
len(X_train)
8982
# 전체 뉴스기사(8982개)의 기사별 단어 개수를 구해서 list에 담아줌
train_len = []
for news in X_train:
train_len.append(len(news))
train_len
.....
41,
25,
69,
41,
142,
232,
52,
221,
87,
44,
35,
16,
306,
108,
41,
102,
629,
27,
254,
95,
65,
261,
25,
287,
416,
94,
63,
27,
133,
51,
...]# 향상된 for문
train_len = [len(news) for news in X_train]
train_len
.....
41,
25,
69,
41,
142,
232,
52,
221,
87,
44,
35,
16,
306,
108,
41,
102,
629,
27,
254,
95,
65,
261,
25,
287,
416,
94,
63,
27,
133,
51,
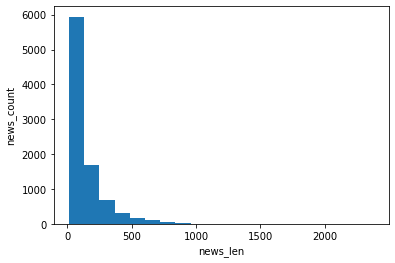
...]print('최대값 : ', max(train_len))
print('최소값 : ', min(train_len))
print('평균값 : ', np.mean(train_len))
print('중앙값 : ', np.median(train_len))
최대값 : 2376
최소값 : 13
평균값 : 145.5398574927633
중앙값 : 95.0# 히스토그램으로 데이터의 밀도를 확인해보자
# 가로축은 뉴스 길이를 각 구간별로 표시, 세로축은 뉴스기사의 개수
plt.hist(train_len, bins=20) # bins : 전체 길이에서 몇 개의 구간으로 나눌지 결정
plt.xlabel('news_len')
plt.ylabel('news_count')
plt.show()
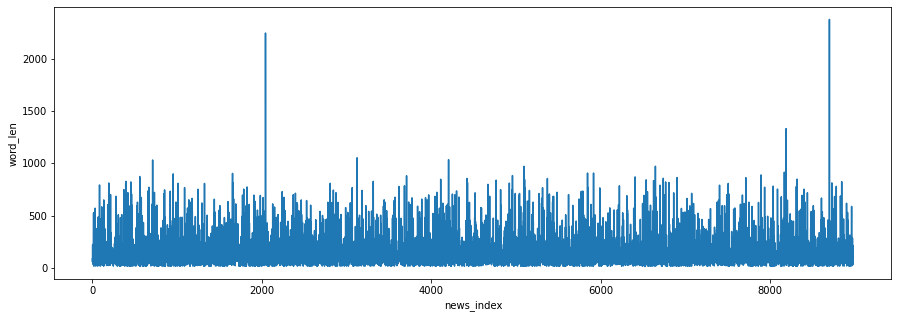
# 라인차트로 각 기사별 단어의 개수가 얼만큼 되는지 대략적으로 파악해보자
# 가로축은 각 뉴스기사의 인덱스 번호, 세로축은 뉴스의 단어 개수
plt.figure(figsize=(15,5))
plt.plot(train_len)
plt.xlabel('news_index')
plt.ylabel('word_len')
plt.show()
문제 데이터 가공
- 전체 단어 개수의 분포를 고려해 가장 많은 개수를 차지하는 120개로 맞춰주자(단어를 120개씩 설정해서 120번씩 순환시켜주자)
- RNN 신경망은 같은 timesteps로 맞춰줘야하기 때문에 사전에 데이터의 길이를 같게 맞춰줘야 함
- 즉, 뉴스 기사의 단어 길이를 120회로 순환 학습하여 어떤 주제의 기사인지를 분류하는 문제라고 볼 수 있음
# RNN신경망의 순환 횟수(시퀀스)를 변경시켜주는 라이브러리
from tensorflow.keras.preprocessing.sequence import pad_sequences
# X_train, X_test에서 시퀀스를 120으로 설정
X_train_pad = pad_sequences(X_train, maxlen=120)
X_test_pad = pad_sequences(X_test, maxlen=120)
len(X_train[0])
87
len(X_train_pad[0]) # 패딩 적용 후 120개로 바뀜 / 87개에서 120개까지 부족한 숫자만큼 0이 앞쪽에 채워진다
# 순환되는 횟수를 늘려줄려고 앞쪽에 0을 채워 120채웠고, 연산은 필요하지 않으므로 앞쪽에 채운다
120
X_train_pad[0]
# RNN에서 padding을 진행하면 앞에서부터 0이 채워짐
# -> 뒤쪽에 0이 들어가면 후반부 연산에서 값이 제대로 전달되지 않을 수 있음
# 초반에는 신경망에 0값이 들어가서 아무런 연산이 일어나지 않고, 실제 연산은 1부터 진행됨
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 27595, 28842,
8, 43, 10, 447, 5, 25, 207, 270, 5,
....................................................................
67, 52, 29, 209, 30, 32, 132, 6, 109,
15, 17, 12], dtype=int32)- timesteps : hello 학습시에는 h,e,l,l 이라는 총 4개의 문자가 들어갔기 때문에 4였고, 현재는 각 뉴스기사의 단어 120개를 120번 순환시킬 것이기 때문에 120으로 설정
- features : hello 학습시에는 원핫인코딩을 통해서 문제 데이터의 컬럼이 9개였기 때문에 9로 설정했고, 로이터 뉴스 문제 데이터는 숫자 하나로만 표시(레이블인코등)되어져 있기 때문에 features는 1이됨
- '입력'은 문제데이터, '출력'은 정답데이터를 보고 생각하자
X_train_pad_reshape = X_train_pad.reshape(8982, 120, 1)
X_test_pad_reshape = X_test_pad.reshape(2246, 120, 1)
X_train_pad_reshape.shape, X_test_pad_reshape.shape
((8982, 120, 1), (2246, 120, 1))
- RNN 신경망에 넣기 전 데이터 가공 단계 완료
RNN 신경망 모델링
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
model = Sequential()
model.add(SimpleRNN(500, input_shape=(120,1)))
# 출력층
# 뉴스기사를 46개의 주제로 분류하는 문제이기 때문에 뉴런의 수는 46개, 활성화함수는 softmax(다중분류)
model.add(Dense(46, activation="softmax"))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='Adam',
metrics=['acc'])
h = model.fit(X_train_pad_reshape, y_train,
validation_split=0.2,
epochs=50,
batch_size=128
)
plt.figure(figsize=(15,5))
# train 데이터
plt.plot(h.history['acc'],
label='acc',
c = 'blue',
marker='.'
)
# val 데이터
plt.plot(h.history['val_acc'],
label='val_acc',
c = 'red',
marker='.'
)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.legend()
plt.show()
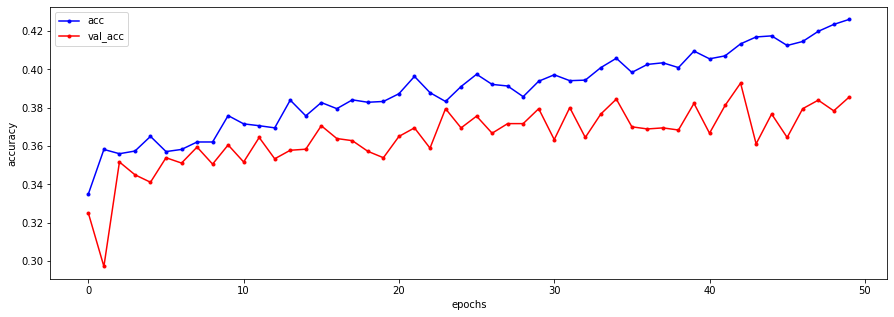
- SimpleRNN만 가지고는 수십 수백개의 단어들로 이루어진 복잡한 데이터를 순서까지 고려해서 다 분류해내기 힘들다

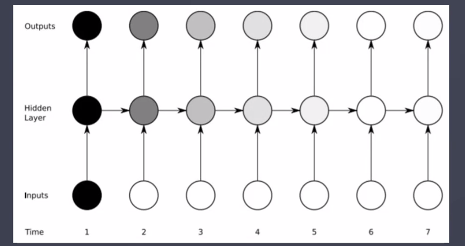
시간이 지나면 이전의
입력값을
잊어버리게 된다





기억1, 2 등등이 희미해지는걸 방지하기위해
LSTM으로 관리

LSTM과 Word Embedding을 적용해보자
- SimpleRNN과는 달리 이전의 중요 데이터들을 모두 기억하여 예측에 반영한다면 좀 더 나은 결과가 나오지 않을까?
- LSTM에 덧붙여 뉴스기사의 단어들을 다양하게 표현할 수 있도록 Embedding도 활용해보자
from tensorflow.keras.layers import LSTM, Embedding
model1 = Sequential()
# input_dim : 데이터 내에서 사용할 최대 단어의 개수(뉴스기사 대부분은 1000개 이하의 단어로 구성되어있다)
# output_dim : 임베딩 층을 통과한 후 생성된 실수의 개수(단어를 얼마만큼 다양하게 표현해줄수 있나)
model1.add(Embedding(input_dim=1000, output_dim=100))
model1.add(LSTM(1000))
model1.add(Dense(46, activation='softmax'))
model1.compile(loss='sparse_categorical_crossentropy',
optimizer='Adam',
metrics=['acc'])
h1 = model1.fit(X_train_pad_reshape, y_train,
validation_split=0.2,
epochs=50,
batch_size=128
)
plt.figure(figsize=(15,5))
# train 데이터
plt.plot(h1.history['acc'],
label='acc',
c = 'blue',
marker='.'
)
# val 데이터
plt.plot(h1.history['val_acc'],
label='val_acc',
c = 'red',
marker='.'
)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.legend()
plt.show()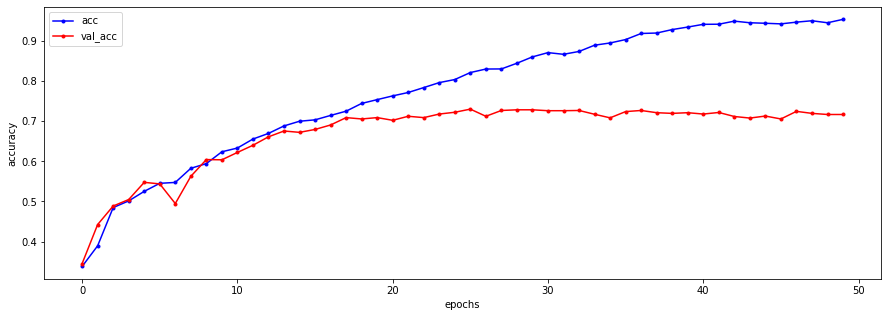
model1.evaluate(X_test_pad_reshape, y_test)
71/71 [==============================] - 1s 18ms/step - loss: 2.0721 - acc: 0.7030
[2.072131395339966, 0.703027606010437]- SimpleRNN에 비해 훨씬 좋은 결과가 나왔지만 아직 텍스트처리 분야는 절대적으로 좋은 수치가 나오기는 힘들고 한창 연구가 진행되고 발전되고 있는 분야임
반응형
'빅데이터 서비스 교육 > 딥러닝' 카테고리의 다른 글
| 딥러닝 OpenCV실습 (0) | 2022.07.28 |
|---|---|
| RNN모델 (0) | 2022.07.26 |
| 전이학습 & 데이터 확장 (0) | 2022.07.25 |
| 딥러닝 다중분류 모델 (3가지 동물 분류) - MLP, CNN, 데이터 확장 예제 (0) | 2022.07.22 |
| CNN (0) | 2022.07.21 |