반응형
보스턴 집값 데이터 예측
from sklearn.datasets import load_boston
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
from sklearn.model_selection import train_test_split
1. 문제정의
- 보스턴 데이터를 활용하여 집값을 예측해보자 (회귀)
2. 데이터 수집
- 로드된 보스턴 데이터 활용
3. 데이터 전처리
- X_train, X_test, y_train, y_test 만들기
4. EDA 생략
5. 모델링
- KNN 회귀모델 (K값은 자유롭게 찾아보자)
from sklearn.neighbors import KNeighborsRegressor
data = load_boston()
data
data.keys()dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])df = pd.DataFrame(data.data,columns=data.feature_names)
df
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT
0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3 396.90 4.98
1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8 396.90 9.14
2 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0 17.8 392.83 4.03
3 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0 18.7 394.63 2.94
4 0.06905 0.0 2.18 0.0 0.458 7.147 54.2 6.0622 3.0 222.0 18.7 396.90 5.33
... ... ... ... ... ... ... ... ... ... ... ... ... ...
501 0.06263 0.0 11.93 0.0 0.573 6.593 69.1 2.4786 1.0 273.0 21.0 391.99 9.67
502 0.04527 0.0 11.93 0.0 0.573 6.120 76.7 2.2875 1.0 273.0 21.0 396.90 9.08
503 0.06076 0.0 11.93 0.0 0.573 6.976 91.0 2.1675 1.0 273.0 21.0 396.90 5.64
504 0.10959 0.0 11.93 0.0 0.573 6.794 89.3 2.3889 1.0 273.0 21.0 393.45 6.48
505 0.04741 0.0 11.93 0.0 0.573 6.030 80.8 2.5050 1.0 273.0 21.0 396.90 7.88
506 rows × 13 columnsX = df
y = data.target
X_train,X_test, y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=1)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
(354, 13)
(152, 13)
(354,)
(152,)
k_model = KNeighborsRegressor()
k_model.fit(X_train,y_train)
KNeighborsRegressor()k_model.score(X_test,y_test) # R2(결정계수) 최고점수는 1
# 50프로의 설명력을 가진다
# 공학 -> 0.7이 넘어야 유의미 , 사회과학 -> 0.3이 넘어야 유의미
0.5099572909288324test_l=[]
train_l=[]
for k in range(1,50,2):
k_model = KNeighborsRegressor(n_neighbors=k)
k_model.fit(X_train,y_train)
s1 = k_model.score(X_train,y_train)
s2 = k_model.score(X_test,y_test)
train_l.append(s1)
test_l.append(s2)
plt.figure(figsize=(10,10))
plt.plot(range(1,50,2),train_l,label='train')
plt.plot(range(1,50,2),test_l,label='test')
plt.legend()
plt.show()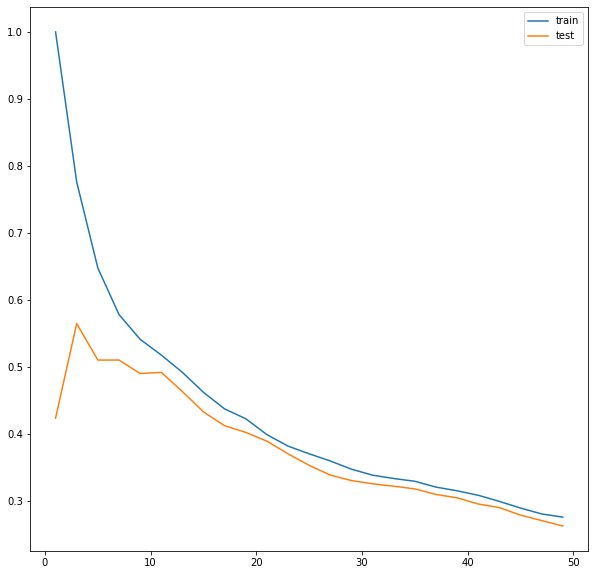
반응형
'빅데이터 서비스 교육 > 머신러닝' 카테고리의 다른 글
| Cross validation (0) | 2022.06.24 |
|---|---|
| 머신러닝 Decision Tree (0) | 2022.06.24 |
| Decision Tree (0) | 2022.06.23 |
| KNN 모델 (0) | 2022.06.22 |
| 머신러닝 (0) | 2022.06.21 |