반응형
목표
- 폐암환자의 생존을 예측하는 신경망 모델을 만들어보자
- keras를 이용해 2진분류 문제를 해결해보자
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# header=None : 데이터프레임에서, 컬럼명을 설정해주는 함수(None : 인덱스 번호로 출력됨)
data = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/빅데이터 13차(딥러닝)/Data/ThoraricSurgery.csv', header=None)
data
# 17번 인덱스 행이 환자의 생존여부를 표시
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
0 293 1 3.80 2.80 0 0 0 0 0 0 12 0 0 0 1 0 62 0
1 1 2 2.88 2.16 1 0 0 0 1 1 14 0 0 0 1 0 60 0
2 8 2 3.19 2.50 1 0 0 0 1 0 11 0 0 1 1 0 66 1
3 14 2 3.98 3.06 2 0 0 0 1 1 14 0 0 0 1 0 80 1
4 17 2 2.21 1.88 0 0 1 0 0 0 12 0 0 0 1 0 56 0
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
465 98 6 3.04 2.40 2 0 0 0 1 0 11 0 0 0 1 0 76 0
466 369 6 3.88 2.72 1 0 0 0 1 0 12 0 0 0 1 0 77 0
467 406 6 5.36 3.96 1 0 0 0 1 0 12 0 0 0 0 0 62 0
468 25 8 4.32 3.20 0 0 0 0 0 0 11 0 0 0 0 0 58 1
469 447 8 5.20 4.10 0 0 0 0 0 0 12 0 0 0 0 0 49 0
470 rows × 18 columns# loc 컬럼명으로 / iloc 컬럼숫자로
X = data.iloc[:,:17] # X = data.iloc[:,:-1] -1은 뒤에서 첫번째행 , 슬라이싱에서 맨뒤 숫자는 포함 안함
y = data.iloc[:,17] # y = data.iloc[:,-1]
X.shape, y.shape
((470, 17), (470,))from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,
test_size=0.3,
random_state=10
)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
(329, 17)
(141, 17)
(329,)
(141,)딥러닝 신경망 모델링
- 1.신경망 구조 설계
- 2.학습/평가 방법 설정
- 3.학습 및 시각화
- 4.모델평가
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
# 신경망 구조 설계
model = Sequential()
# input_dim : 입력되는 데이터의 특성 개수를 설정
# activation : 활성화 함수를 설정(들어온 자극(데이터)에 대한 응답여부를 결정하는 함수)
# 입력층(input_dim) + 중간(Dense) 1개층
model.add(Dense(10,input_dim=17, activation='sigmoid'))
# 중간층
model.add(Dense(6,activation='sigmoid'))
model.add(Dense(3,activation='sigmoid'))
# 출력층
model.add(Dense(1,activation='sigmoid'))
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 10) 180
W값: 17개의 특성이 10개에 들어가고(17x10)
b값: 10개 -> 총180개
dense_1 (Dense) (None, 6) 66
(10x6) + 6 -> 66개
dense_2 (Dense) (None, 3) 21
dense_3 (Dense) (None, 1) 4
=================================================================
Total params: 271
Trainable params: 271
Non-trainable params: 0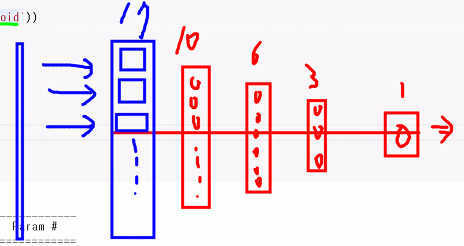
입력층 특성17개
Dense 중간층
(10,6,3) 3개
출력층 (1) 1개
2진분류에서는 출력층이 하나여야 1과 0을 분류 가능하다
출력층은 문제유형에 따라 달라져야 한다
activation(활성화함수) - 자극에 대한 반응여부를 결정하는 함수
- 1.회귀 : linear(항등함수) -> 신경망에서 도출된 수치값을 그대로 예측에 사용함
- 2.분류 : 딥러닝은 선형모델을 기반으로 만들어졌기 때문에 여기서 도출된 수치값으로는 분류문제를 해결할 수 없음
- 분류 모델은 확률 정보를 가지고 판단하는 것이 더욱 정확
- 이진분류 : sigmoid -> 0 또는 1로 분류 (0.5를 기준으로 높고 낮음에 따라 판단)
# 학습 및 평가방법 설정
# binary_crossentropy : 2진분류에 사용하는 손실함수
# → 오차의 평균을 구하는 것은 mse와 같지만 0~1사이의 값으로 변환한 후에 평균오차를 구함(그래야 이진분류 0또는1로 분류하기 편하니까)
model.compile(loss='binary_crossentropy',
optimizer='SGD', # 최적화 함수 : 확률적 경사하강법
metrics=['acc'] # metrics : 평가방법을 설정(분류 문제이기 때문에 정확도를 넣어줌)
)
# 학습
h= model.fit(X_train, y_train, epochs=100)
Epoch 1/100
11/11 [==============================] - 1s 2ms/step - loss: 32.0749 - acc: 0.1368
Epoch 2/100
11/11 [==============================] - 0s 2ms/step - loss: 8.3654 - acc: 0.1368
Epoch 3/100
11/11 [==============================] - 0s 2ms/step - loss: 1.8047 - acc: 0.1368
Epoch 4/100
11/11 [==============================] - 0s 3ms/step - loss: 1.1417 - acc: 0.1398
Epoch 5/100
11/11 [==============================] - 0s 3ms/step - loss: 0.8999 - acc: 0.1429
Epoch 6/100
11/11 [==============================] - 0s 3ms/step - loss: 0.7749 - acc: 0.2036
Epoch 7/100
.................................................................................
Epoch 93/100
11/11 [==============================] - 0s 3ms/step - loss: 0.3936 - acc: 0.8632
Epoch 94/100
11/11 [==============================] - 0s 2ms/step - loss: 0.3942 - acc: 0.8632
Epoch 95/100
11/11 [==============================] - 0s 3ms/step - loss: 0.3940 - acc: 0.8632
Epoch 96/100
11/11 [==============================] - 0s 3ms/step - loss: 0.3934 - acc: 0.8632
Epoch 97/100
11/11 [==============================] - 0s 3ms/step - loss: 0.3935 - acc: 0.8632
Epoch 98/100
11/11 [==============================] - 0s 2ms/step - loss: 0.3933 - acc: 0.8632
Epoch 99/100
11/11 [==============================] - 0s 2ms/step - loss: 0.3930 - acc: 0.8632
Epoch 100/100
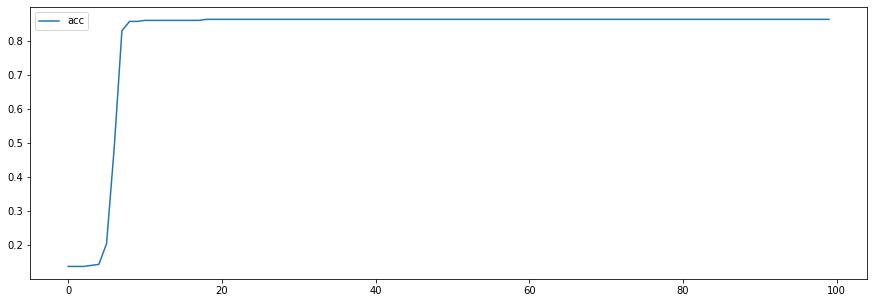
11/11 [==============================] - 0s 3ms/step - loss: 0.3927 - acc: 0.8632plt.figure(figsize=(15,5))
plt.plot(h.history['acc'], label='acc')
plt.legend()
plt.show()
model.evaluate(X_test,y_test)
5/5 [==============================] - 0s 5ms/step - loss: 0.4880 - acc: 0.8227
[0.48796752095222473, 0.8226950168609619]
반응형
'빅데이터 서비스 교육 > 딥러닝' 카테고리의 다른 글
| 활성화함수 (0) | 2022.07.14 |
|---|---|
| 딥러닝 유방암 데이터 분류 예제 (0) | 2022.07.14 |
| 퍼셉트론, 다층 퍼셉트론 (0) | 2022.07.13 |
| 딥러닝 기본 실습 (0) | 2022.07.12 |
| 딥러닝 (0) | 2022.07.12 |