반응형
이미지 크롤링
# !pip install selenium
from selenium import webdriver as wb # 브라우저를 조작하는 도구
from selenium.webdriver.common.keys import Keys # 키 입력을 도와주는 도구(키보드)
from bs4 import BeautifulSoup as bs # 문서를 파싱해서 선택자 활용을 도와주는 도구
from tqdm import tqdm # 반복문 진행 정도를 시각화해주는 도구
from urllib.request import urlretrieve # 이미지 다운로드를 도와주는 도구
import time # 시간제어 도구
import os # 폴더 생성,삭제,이동 등을 도와주는 도구
keyword = "수달"
# 이미지가 저장될 폴더 생성
# 해당 폴더가 있는지 확인
if os.path.isdir('./{}'.format(keyword)) == False :
os.mkdir('./{}'.format(keyword)) # 폴더 생성url = 'https://www.google.com/search?q={}&source=lnms&tbm=isch&sa=X&ved=2ahUKEwjs85-GsN7vAhX4xYsBHR6aBg0Q_AUoAXoECAEQAw&biw=1745&bih=852'.format(keyword)
driver = wb.Chrome() # 브라우져 생성
driver.get(url) # url 요청
time.sleep(5) # 페이지 로딩까지 5초 대기
cnt = 0
pre_img_src = [] # 이전에 다운로드된 경로
for j in range(10) :
img_html = bs(driver.page_source,'html.parser')
# 이미지 태그 수집
images = img_html.select('img.rg_i.Q4LuWd')
# 이미지 태그의 src 속성 값 추출
img_src = []
for img in images :
src = img.get('src')
if src != None : # img 태그에 src 속성이 없는 경우
if src not in pre_img_src : # 이전에 다운로드한 경로에 있는지 검사
img_src.append(src)
else : # img 태그에 src 속성이 있는 경우
src = img.get('data-src')
if src not in pre_img_src :
img_src.append(src)
# 파일 다운로드
# img_src를 반복문으로 돌면서 저장, tqdm 사용
for src in tqdm(img_src) :
cnt += 1
try :
urlretrieve(src,'./{}/{}.png'.format(keyword,cnt))
except :
print("수집불가")
continue
pre_img_src += img_src # 다운로드한 경로를 이전 리스트에 추가
# 화면 스크롤
for i in range(6):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# driver.find_element_by_css_selector('body').send_keys(Keys.PAGE_DOWN)
time.sleep(1)이미지 데이터 전처리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image
# os : 파일 및 폴더 처리에 관련된 라이버르리
import os
# 각 폴더별 경로 지정
procyonoides_dir = '너구리/'
suricatta_dir = '미어캣/'
otter_dir = '수달/'
# os.listdir : 해당 경로에 있는 파일명들을 리스트로 순서대로 저장
procyonoides_fnames = os.listdir(Nyctereutes_dir)
suricatta_fnames = os.listdir(suricatta_dir)
otter_fnames = os.listdir(otter_dir)
otter_fnames
#os.path.join : 폴더 경로와 파일명을 결합
test_path = os.path.join(procyonoides_dir,procyonoides_fnames[50] )
test_path'너구리/144.png'
# 이미지를 로딩하는 함수(데이터로드, 파일 오픈 및 사이즈 조정, 배열로 변경)
def load_images(folder_path, file_names, img_size_shape=(224,224)):
images = []
for i in file_names:
# 폴더 경로 + 파일명 합치기
path = os.path.join(folder_path, i)
# 파일 오픈 및 크기 조정(resize: 파일 형태(사이즈)를 변경)
img = Image.open(path).resize(img_size_shape).convert('RGB')
# numpy배열로 변경후에 리스트에 저장
images.append(np.array(img))

# 리스트 자체도 numpy배열로 변경해서 반환
return np.array(images)
train_procyonoides = load_images(procyonoides_dir,procyonoides_fnames)
train_suricatta = load_images(suricatta_dir, suricatta_fnames)
train_otter = load_images(otter_dir, otter_fnames)
print(train_procyonoides.shape)
print(train_suricatta.shape)
print(train_otter.shape)(400, 224, 224, 3)
(400, 224, 224, 3)
(400, 224, 224, 3)X = np.concatenate([train_procyonoides, train_suricatta, train_otter])
y = np.array([0]*400+[1]*400+[2]*400)
print(X.shape)
print(y.shape)
(1200, 224, 224, 3)
(1200,)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,
test_size=0.2,
random_state=11)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)(960, 224, 224, 3)
(240, 224, 224, 3)
(960,)
(240,)NPZ파일로 변환(Numpy Zip)
- 압축된 배열 파일로 데이터를 변환
np.savez_compressed('animals.npz', # 저장될 폴더 경로 및 파일명 설정
X_train = X_train,
X_test = X_test,
y_train = y_train,
y_test = y_test)목표
- 크롤링한 3종류의 이미지 데이터를 분류하는 신경망 모델을 만들어보자
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import fashion_mnist
data = np.load("/content/drive/MyDrive/Colab Notebooks/빅데이터 13차(딥러닝)/Data/animals.npz")
X_train = data['X_train']
X_test = data['X_test']
y_train = data['y_train']
y_test = data['y_test']
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
(960, 224, 224, 3)
(240, 224, 224, 3)
(960,)
(240,)MLP로 신경망 모델 만들기
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Flatten
model = Sequential()
model.add(Flatten(input_shape=(224,224,3)))
model.add(Dense(300, activation="relu"))
model.add(Dense(150, activation="relu"))
model.add(Dense(50, activation="relu"))
model.add(Dense(3, activation="softmax"))
# 기존 categorical_crossentropy에 레이블들의 원핫인코딩까지 sparse_를 쓰면 자동으로 지원
model.compile(loss="sparse_categorical_crossentropy",
optimizer="Adam",
metrics=['acc']
)
from sklearn.utils import validation
from sklearn.model_selection import train_test_split
h = model.fit(X_train,y_train,
batch_size=128,
epochs=50,
validation_split=0.2
)
Epoch 1/50
6/6 [==============================] - 3s 72ms/step - loss: 17426.5371 - acc: 0.2930 - val_loss: 7392.8706 - val_acc: 0.3281
Epoch 2/50
6/6 [==============================] - 0s 36ms/step - loss: 6421.2710 - acc: 0.3255 - val_loss: 6963.2598 - val_acc: 0.2812
Epoch 3/50
6/6 [==============================] - 0s 34ms/step - loss: 6894.0620 - acc: 0.3464 - val_loss: 7319.2251 - val_acc: 0.3906
Epoch 4/50
6/6 [==============================] - 0s 31ms/step - loss: 5149.3687 - acc: 0.3333 - val_loss: 4044.2434 - val_acc: 0.3854
Epoch 5/50
6/6 [==============================] - 0s 28ms/step - loss: 5796.9009 - acc: 0.3724 - val_loss: 7200.7622 - val_acc: 0.3906
Epoch 6/50
6/6 [==============================] - 0s 29ms/step - loss: 6574.7090 - acc: 0.3333 - val_loss: 9707.5273 - val_acc: 0.3021
...............................................................................................
Epoch 50/50
6/6 [==============================] - 0s 28ms/step - loss: 90.8250 - acc: 0.6862 - val_loss: 250.8062 - val_acc: 0.4323plt.figure(figsize=(15,5))
# train 데이터
plt.plot(h.history['acc'], label=['acc'],
c='blue', marker='.')
# val 데이터
plt.plot(h.history['val_acc'], label=['val_acc'],
c='red', marker='.')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show()

다양한 이미지를 가지고 왔기 때문에 정확도가 높지 않다
pre = model.predict(X_test)
pre
# 정확도 외에도 정밀도, 재현율, F-score 까지 확인해보자
from sklearn.metrics import classification_report
# np.argmax : 출력된 확률값 중 가장 큰 수치값의 인덱스를 반환
# axis=1 : pre가 2차원 배열이므로 내부 배열들만(1차원) 보겠다는 뜻
np.argmax(pre, axis=1)
array([2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])#classification_report(평가용정답, 예측한 정답)
print(classification_report(y_test,np.argmax(pre, axis=1)))
# precision(정밀도) : 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율
# recall(재현율) : 실제 True인 것들 중에서 모델이 True라고 예측한 것의 비율
# support : 레이블의 개수
# -> 결국은 pre값이 각 레이블에 대한 확률 값으로 나오기 때문에 그 중 가장 높은 수치의 인덱스를 반환하여 y_test랑 비교하는 방식
precision recall f1-score support
0 0.00 0.00 0.00 87
1 0.00 0.00 0.00 79
2 0.31 1.00 0.47 74
accuracy 0.31 240
macro avg 0.10 0.33 0.16 240
weighted avg 0.10 0.31 0.15 240- 기존 MLP로는 3채널이고 배경이 다양한 이미지 데이터들을 분류하는데 어려움이 있다
CNN을 적용하여 신경망을 모델링해보자
from tensorflow.keras.layers import Conv2D, MaxPool2D, Flatten, Dropout
cnn_model = Sequential()
# 1. 특성추출부(Conv - 특징이 되는 정보를 부각시켜 추출함)
cnn_model.add(Conv2D(input_shape=(224,224,3),
# 필터(돋보기)의 개수 -> 추출하는 특징의 개수를 설정
filters=128,
# 필터의 크기 설정(행,열)
kernel_size=(3,3),
# same : 원본 데이터의 크기에 맞게 알아서 패딩을 적용('valid' -> 패딩적용X)
padding='same',
activation='relu'
))
# 2. 특성추출부(Pooling - 불필요한 정보 삭제)
# pool_size : 디폴트 값이 2(필터 크기가 2x2)
cnn_model.add(MaxPool2D())
cnn_model.add(Conv2D(filters=256,
kernel_size=(3,3),
padding='same',
activation='relu'
))
cnn_model.add(MaxPool2D())
# Dropout : 신경망의 전체 뉴런중 일부(20%)를 학습이 불가하도록 만들어주는 명령
# -> 신경망의 복잡도를 낮춰서 좀 더 가볍게 동작시키고 과대적합을 해소하는데 도움을 줌
cnn_model.add(Dropout(0.2))
cnn_model.add(Conv2D(filters=128,
kernel_size=(3,3),
padding='same',
activation='relu'
))
cnn_model.add(MaxPool2D())
cnn_model.add(Conv2D(filters=64,
kernel_size=(3,3),
padding='same',
activation='relu'
))
cnn_model.add(MaxPool2D())
# 분류기(MLP : 다층퍼셉트론)
cnn_model.add(Flatten())
cnn_model.add(Dense(128, activation='relu'))
cnn_model.add(Dense(64, activation='relu'))
cnn_model.add(Dense(32, activation='relu'))
cnn_model.add(Dense(3, activation='softmax'))
cnn_model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 224, 224, 128) 3584
max_pooling2d (MaxPooling2D (None, 112, 112, 128) 0
)
conv2d_1 (Conv2D) (None, 112, 112, 256) 295168
max_pooling2d_1 (MaxPooling (None, 56, 56, 256) 0
2D)
dropout (Dropout) (None, 56, 56, 256) 0
conv2d_2 (Conv2D) (None, 56, 56, 128) 295040
max_pooling2d_2 (MaxPooling (None, 28, 28, 128) 0
2D)
conv2d_3 (Conv2D) (None, 28, 28, 64) 73792
max_pooling2d_3 (MaxPooling (None, 14, 14, 64) 0
2D)
flatten_1 (Flatten) (None, 12544) 0
dense_4 (Dense) (None, 128) 1605760
dense_5 (Dense) (None, 64) 8256
dense_6 (Dense) (None, 32) 2080
dense_7 (Dense) (None, 3) 99
=================================================================
Total params: 2,283,779
Trainable params: 2,283,779
Non-trainable params: 0cnn_model.compile(loss='sparse_categorical_crossentropy',
optimizer='Adam',
metrics=['acc'])
h= cnn_model.fit(X_train,y_train,
validation_split=0.2,
batch_size=128,
epochs=50)
plt.figure(figsize=(15,5))
# train 데이터
plt.plot(h.history['acc'], label=['acc'],
c='blue', marker='.')
# val 데이터
plt.plot(h.history['val_acc'], label=['val_acc'],
c='red', marker='.')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show()
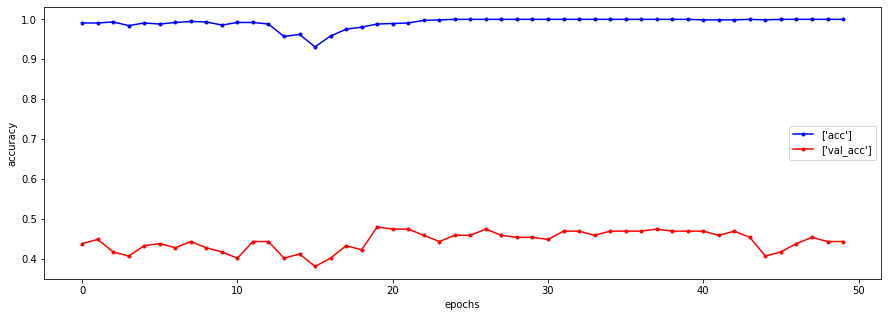
pre = cnn_model.predict(X_test)
from sklearn.metrics import classification_report
print(classification_report(y_test, np.argmax(pre, axis=1)))
precision recall f1-score support
0 0.48 0.51 0.49 87
1 0.53 0.49 0.51 79
2 0.45 0.46 0.46 74
accuracy 0.49 240
macro avg 0.49 0.49 0.49 240
weighted avg 0.49 0.49 0.49 240직접 만든 CNN 모델로는 한번에 좋은 결과를 보긴 힘들다
CNN 전이학습 모델 활용하기(VGG160)
- ImageNet challenge 대회에서 2014년도 준우승한 VGG16모델을 활용해보자
from tensorflow.keras.applications import VGG16
pre_trained_model = VGG16(input_shape=(224,224,3),
include_top=False,
weights='imagenet'
)
# include_top=False : 불러온 모델의 MLP층을 사용하지 않고 특성추출부만 사용(특성추출방식)
# False : 상단부(MLP)를 쓰지 않겠다는 뜻
# -> 기존 이미지넷 대회에서는 1000가지의 이미지를 분류했으나 우리는 3가지 동물로만 분류하기 때문에
# MPL층을 우리에게 맞게 설정해줘야 함
# weights='imagenet' : 이미지넷 대회에서 학습된 가중치(w)를 그대로 가져와서 사용
pre_trained_model.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________cnn_model2 = Sequential()
#특성추출부
cnn_model2.add(pre_trained_model)
# MLP층
cnn_model2.add(Flatten())
cnn_model2.add(Dense(128, activation='relu'))
cnn_model2.add(Dense(64, activation='relu'))
cnn_model2.add(Dense(32, activation='relu'))
cnn_model2.add(Dense(3, activation='softmax'))
cnn_model2.summary()Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 7, 7, 512) 14714688
flatten_2 (Flatten) (None, 25088) 0
dense_8 (Dense) (None, 128) 3211392
dense_9 (Dense) (None, 64) 8256
dense_10 (Dense) (None, 32) 2080
dense_11 (Dense) (None, 3) 99
=================================================================
Total params: 17,936,515
Trainable params: 17,936,515 #학습 시킬수 있는 parameter
Non-trainable params: 0 #학습 시킬수 없는 parameter
_________________________________________________________________MLP층만 수정하고 특성추출부는 학습이 잘 된것을 가져왔는데
역전파로 학습시키고 이를 토대로 w,b값을 다시 바꾸면 잘 학습된 특성추출부를 가져온 의미가 없다.
# 사전에 학습된 vgg16모델을 불러와서 재학습이 불가능하도록 동결(잘 학습된 w,b값을 그대로 사용하기 위해서)
# -> 동결을 시키지 않게 되면 새롭게 만들어준 MLP층과 재학습하게 되므로 잘 학습된 w,b값이 뒤틀려 버린다
pre_trained_model.trainable = False
pre_trained_model.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
.................................................................
=================================================================
Total params: 14,714,688
Trainable params: 0
Non-trainable params: 14,714,688 # non trainalbe params로 바뀜
_________________________________________________________________cnn_model2.compile(loss='sparse_categorical_crossentropy',
optimizer='Adam',
metrics=['acc'])
h2 = cnn_model2.fit(X_train, y_train,
validation_split=0.2,
batch_size=128,
epochs=50)
plt.figure(figsize=(15,5))
# train 데이터
plt.plot(h2.history['acc'], label=['acc'],
c='blue', marker='.')
# val 데이터
plt.plot(h2.history['val_acc'], label=['val_acc'],
c='red', marker='.')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show()
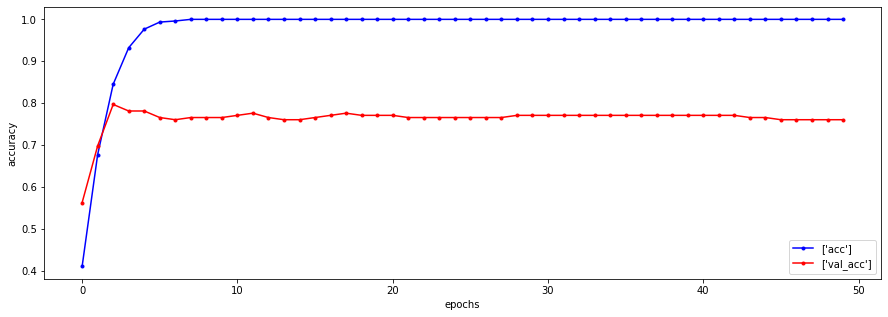
pre = cnn_model2.predict(X_test)
print(classification_report(y_test, np.argmax(pre, axis=1)))
precision recall f1-score support
0 0.76 0.78 0.77 87
1 0.90 0.70 0.79 79
2 0.71 0.85 0.77 74
accuracy 0.78 240
macro avg 0.79 0.78 0.78 240
weighted avg 0.79 0.78 0.78 240- 결과는 기존보다 좋아졌지만 조금 더 튜닝해보자(미세조정방식 적용)
pre_trained_model = VGG16(input_shape=(224,224,3),
include_top=False,
weights='imagenet')
pre_trained_model.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________# VGG16 모델의 각 층별 이름을 출력
for layer in pre_trained_model.layers :
print(layer.name)
input_2
block1_conv1
block1_conv2
block1_pool
block2_conv1
block2_conv2
block2_pool
block3_conv1
block3_conv2
block3_conv3
block3_pool
block4_conv1
block4_conv2
block4_conv3
block4_pool
block5_conv1
block5_conv2
block5_conv3
block5_poolfor layer in pre_trained_model.layers:
if layer.name == 'block5_conv3' :
layer.trainable = True # 마지막층만 학습 가능하게
else :
layer.trainable = False
pre_trained_model.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
..............................................................
=================================================================
Total params: 14,714,688
Trainable params: 2,359,808
Non-trainable params: 12,354,880
_________________________________________________________________cnn_model3 = Sequential()
cnn_model3.add(pre_trained_model)
cnn_model3.add(Flatten())
cnn_model3.add(Dense(128, activation='relu'))
cnn_model3.add(Dense(64, activation='relu'))
cnn_model3.add(Dense(32, activation='relu'))
cnn_model3.add(Dense(3, activation='softmax'))
cnn_model3.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 7, 7, 512) 14714688
flatten_3 (Flatten) (None, 25088) 0
dense_12 (Dense) (None, 128) 3211392
dense_13 (Dense) (None, 64) 8256
dense_14 (Dense) (None, 32) 2080
dense_15 (Dense) (None, 3) 99
=================================================================
Total params: 17,936,515
Trainable params: 5,581,635
Non-trainable params: 12,354,880
_________________________________________________________________cnn_model3.compile(loss='sparse_categorical_crossentropy',
optimizer='Adam',
metrics=['acc'])
h3 = cnn_model3.fit(X_train,y_train,
validation_split=0.2,
batch_size=128,
epochs=50)
plt.figure(figsize=(15,5))
# train 데이터
plt.plot(h3.history['acc'], label=['acc'],
c='blue', marker='.')
# val 데이터
plt.plot(h3.history['val_acc'], label=['val_acc'],
c='red', marker='.')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show()
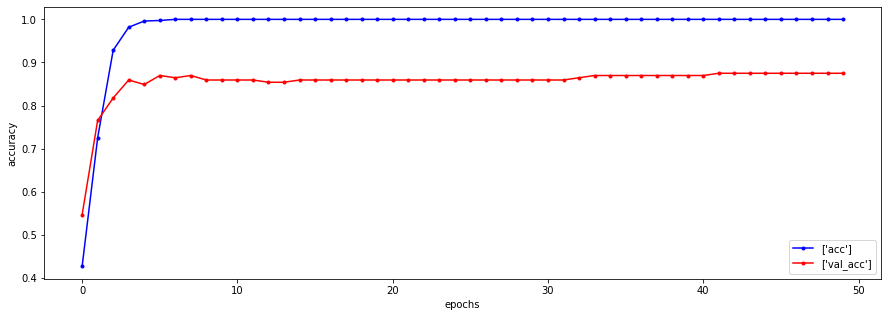
pre = cnn_model3.predict(X_test)
print(classification_report(y_test, np.argmax(pre, axis=1)))
precision recall f1-score support
0 0.78 0.82 0.80 87
1 0.82 0.82 0.82 79
2 0.87 0.82 0.85 74
accuracy 0.82 240
macro avg 0.82 0.82 0.82 240
weighted avg 0.82 0.82 0.82 240데이터 증강(이미지 증식)
- 모델의 과대적합을 방지하기 위한 기법 중 하나
- 유사한 이미지를 생성하여 학습에 용이하게 만들어주고 학습 데이터의 양 자체를 늘려주는 효과
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# ImageDataGenerator : 이미지 데이터를 생성하기 위한 조건을 설정하는 함수
aug = ImageDataGenerator(rotation_range=30, # 이미지 회전 각도
width_shift_range=0.2, # 20% 내외 수평이동
height_shift_range=0.2, # 20% 내외 수직이동
zoom_range=0.2, # 0.8 ~ 1.2배로 축소/확대
horizontal_flip=True, # 수평방향으로 뒤집기
fill_mode='nearest' # 이미지가 변형되면서 비는 공간에 가장 가까운 픽셀값으로 채워줌
)
for layer in pre_trained_model2.layers:
if layer.name == 'block5_conv3' :
layer.trainable = True # 마지막층만 학습 가능하게
else :
layer.trainable = False
cnn_model4 = Sequential()
cnn_model4.add(pre_trained_model2)
cnn_model4.add(Flatten())
cnn_model4.add(Dense(128, activation='relu'))
cnn_model4.add(Dense(64, activation='relu'))
cnn_model4.add(Dense(32, activation='relu'))
cnn_model4.add(Dense(3, activation='softmax'))
cnn_model4.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 7, 7, 512) 14714688
flatten_2 (Flatten) (None, 25088) 0
dense_8 (Dense) (None, 128) 3211392
dense_9 (Dense) (None, 64) 8256
dense_10 (Dense) (None, 32) 2080
dense_11 (Dense) (None, 3) 99
=================================================================
Total params: 17,936,515
Trainable params: 5,581,635
Non-trainable params: 12,354,880
_________________________________________________________________cnn_model4.compile(loss='sparse_categorical_crossentropy',
optimizer='Adam',
metrics=['acc'])
len(X_train)
960
# flow : ImageDataGenerator로 설정한 조건을 통해 이미지를 생성하여 학습에 적용시켜주는 함수
cnn_model4.fit(aug.flow(X_train,y_train, batch_size=128),
# 한 epoch 당 7.5번 돌고 끝나게 됨(128*7.5로 총 960개의 새로운 이미지를 생성)
steps_per_epoch=len(X_train) / 128,
epochs=50
)
# 1epoch 때 증식된 이미지 960개로 학습, 2epoch 때 960개가 추가되어서 총 1920개로 학습 .... 이렇게 반복
pre = cnn_model4.predict(X_test)
print(classification_report(y_test, np.argmax(pre, axis=1)))
precision recall f1-score support
0 0.78 0.79 0.79 87
1 0.87 0.85 0.86 79
2 0.85 0.86 0.86 74
accuracy 0.83 240
macro avg 0.84 0.84 0.84 240
weighted avg 0.83 0.83 0.83 240반응형
'빅데이터 서비스 교육 > 딥러닝' 카테고리의 다른 글
| RNN모델 (0) | 2022.07.26 |
|---|---|
| 전이학습 & 데이터 확장 (0) | 2022.07.25 |
| CNN (0) | 2022.07.21 |
| 활성화함수, 최적화함수 비교 및 최적화 모델 찾기 (0) | 2022.07.21 |
| 활성화함수, 최적화 함수 (0) | 2022.07.19 |