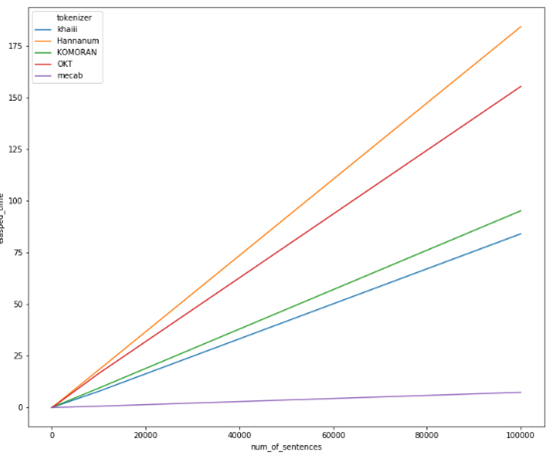
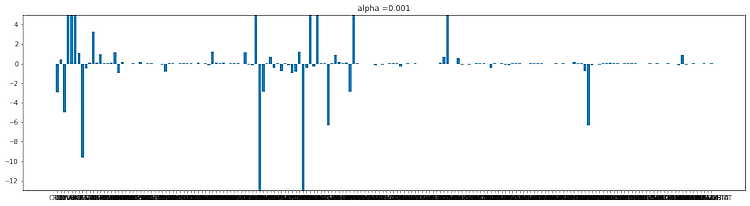
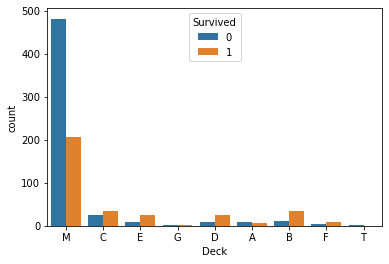
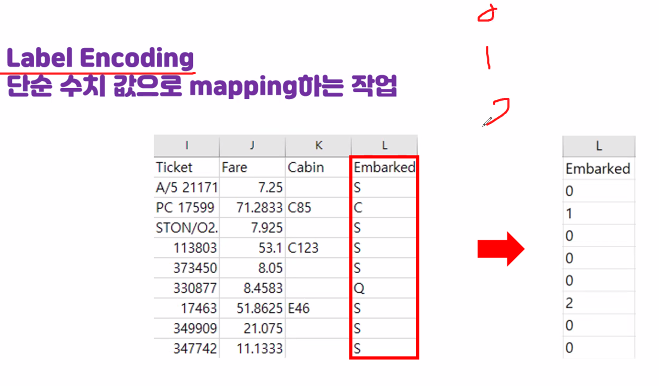
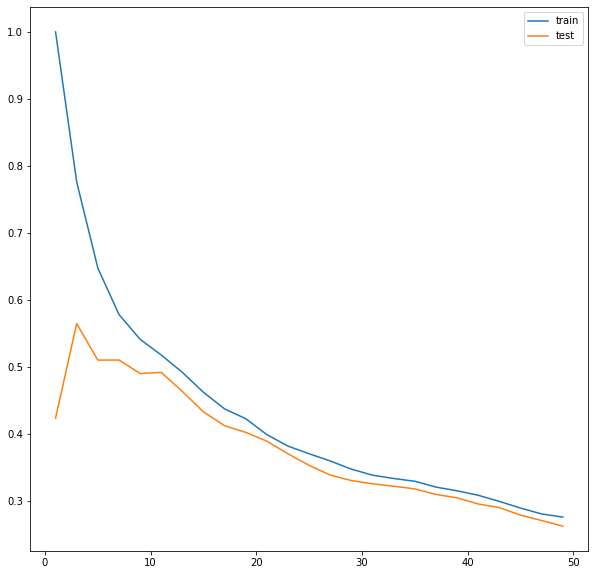
konlpy 설치 Konlpy(코엔엘파이): 한글 형태소 분석기 !pip install konlpy from konlpy.tag import Okt # Open Korean Text: 트위터에서 만든 오픈소스 한국어 처리기 okt = Okt() okt.morphs('한글 형태소 분석기') #morphs : 형태소 분석기 # 의미를 가지는 가장 작은 단위로 쪼갠다 ['한글', '형태소', '분석', '기'] okt.nouns('한글 형태소 분석기') #nouns : 명사 추출 ['한글', '형태소', '분석', '기'] okt.pos('한글 형태소 분석기') #pos : 매핑된 품사 [('한글', 'Noun'), ('형태소', 'Noun'), ('분석', 'Noun'), ('기', 'Noun')] okt...