앙상블 모델

앙상블 모델은 여러 모델을 연결하여 쓴다
앙상블 - 보팅(Voting)
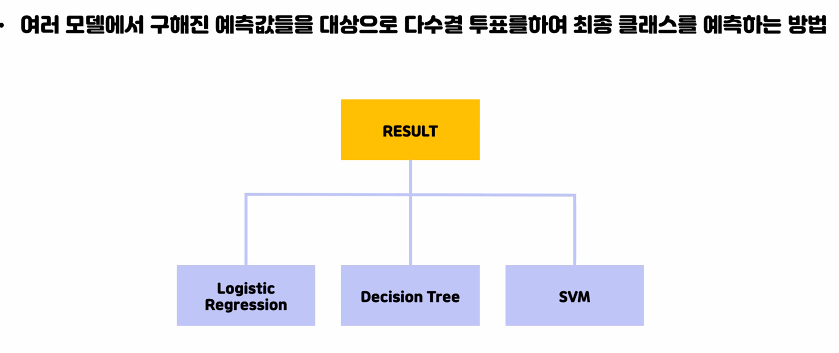
하드보팅
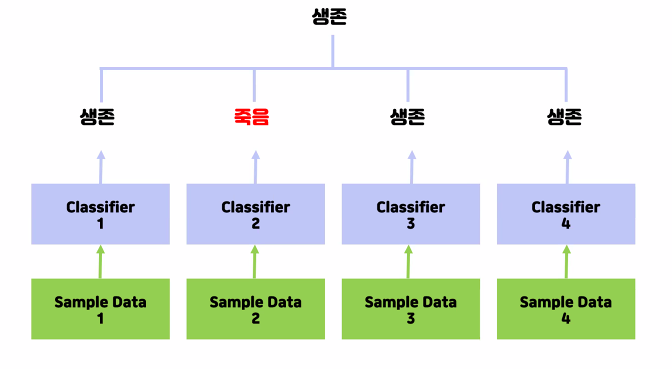

소프트 보팅


배깅(Baggin)
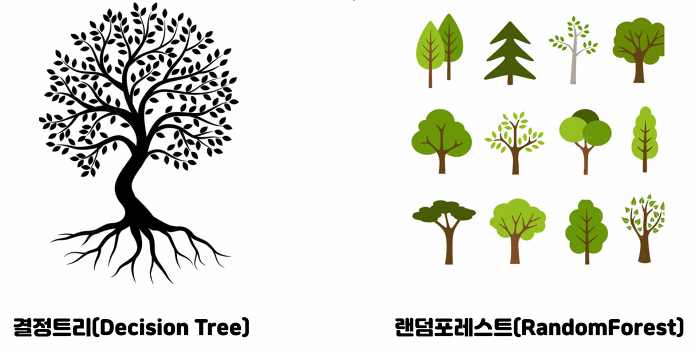
결정트리는
하나의 나무
랜덤포레스트모델은
각각 다른 나무들
각 트리는 학습 데이터를 다르게 해서 트리들이 서로 다르게 만든다.
특성을 랜던하게 학습해서 트리들이
서로 다르게 만든다.

보팅과 랜덤포레스트의 다른점 : 랜덤포레스트는 서로다른 결정트리들을 모델로 사용
보팅은 여러 모델을 사용


랜덤으로 뽑은 데이터가 여러개의 모델에 들어가고난 결과를 과반수로 채택한다


보팅, 배깅은 병렬 구조로 각 모델이 옆모델의 결과에 영향을 끼치지 않는다.
부스팅(Boosting)
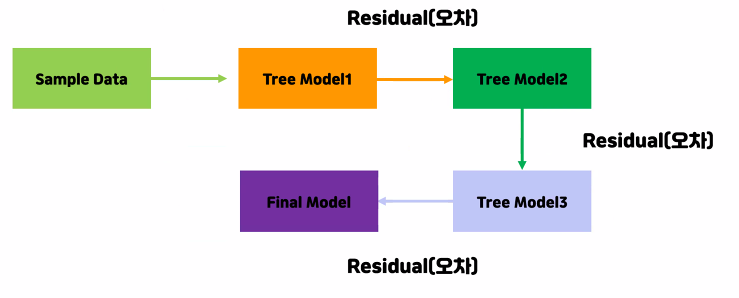
하나의 샘플 데이터만 사용
각 모델에서 오차가 나오면 그 기억을 다음 모델에 보내 오차를 점점 줄여간다 -> 성능이 높다



예측속도 -> predict() / 학습속도 -> fit()


ex06_타이타닉 생존자 예제를 앙상블 사용해서
ex10_타이타닉 생존자분석 앙상블 사용
앙상블
from sklearn.ensemble import VotingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
knn = KNeighborsClassifier()
tree = DecisionTreeClassifier()
forest = RandomForestClassifier()
voting_model = VotingClassifier(
estimators= [
('knn1',knn),
('tree1',tree),
('forest1',forest)
],
voting = 'soft' #default값은 hard
)
voting_model.fit(X_train,y_train)
VotingClassifier(estimators=[('knn1', KNeighborsClassifier()),
('tree1', DecisionTreeClassifier()),
('forest1', RandomForestClassifier())],
voting='soft')voting_model.predict(X_test)
array([0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1,
0, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0,
1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0,
1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1,
..............................................................................
0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0,
0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1],
dtype=int64)forest_model = RandomForestClassifier(n_estimators=1000, #만들 모델의 개수
#데이터를 다르게해서 서로 다른트리로 만든다
max_depth= 5,
min_samples_split=15,
max_features=0.7 #특성을 다르게해서 서로 다른 트리를 만든다.
)
from sklearn.model_selection import GridSearchCV
grid = {
'n_estimators':[1000,1500,2000,2500],
'max_depth': [5,10,15],
'min_samples_split':[15,30],
'max_features':[0.5,0.7]
}
grid_s = GridSearchCV(forest_model,grid,cv=3) #cv : 교차 검증에서 몇개로 분할되는지 지정한다.
grid_s.fit(X_train,y_train)
print('best score : ',grid_s.best_score_)
print('best parmas : ',grid_s.best_params_)
best score : 0.8395061728395062
best parmas : {'max_depth': 10, 'max_features': 0.7, 'min_samples_split': 15, 'n_estimators': 1000}final_forest = RandomForestClassifier(n_estimators=1000, #만들 모델의 개수
max_depth= 10,
min_samples_split=15,
max_features=0.7
)
final_forest.fit(X_train,y_train)
RandomForestClassifier(max_depth=10, max_features=0.7, min_samples_split=15,
n_estimators=1000)final_forest.predict(X_test)
array([0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1,
1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1,
1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1,
..........................................................................
1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1,
0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0],
dtype=int64)boosting package 설치
#!pip install lightgbm 학습시간이 XGBoost보다 짧다, 성능은 큰 차이를 보이지않음
#!pip install XGBoost
#이 두개가 boosting 모델에서 자주 쓰는것들
from lightgbm import LGBMClassifier
# 단점 : 일반적으로 10000건 이하의 데이터 세트를 다루는 경우 과적합 문제 발생이 쉽다
from lightgbm import LGBMClassifier
lgbm = LGBMClassifier(n_estimators = 400) #boosting_type: str='gbdt' : 경사하강법
lgbm.fit(X_train,y_train)
lgbm.predict(X_test)
array([0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0,
1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1,
...................................................................
1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1,
0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1],
dtype=int64)
'빅데이터 서비스 교육 > 머신러닝' 카테고리의 다른 글
| 네이버 영화 리뷰데이터(konlpy활용) 실습 (0) | 2022.07.07 |
|---|---|
| 텍스트 마이닝 (0) | 2022.07.06 |
| Linear Model 실습 (0) | 2022.07.01 |
| Linear Model (0) | 2022.06.29 |
| 예제 타이타닉 생존자 예측분석 (0) | 2022.06.24 |