
ex) 챗봇, 빅스비, 시리


ex11_영화리뷰데이터 다루기(비정형데이터,텍스트마이닝)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option('display.max_colwidth', None)
1. 문제정의
- 영화리뷰 데이터셋을 활용해 긍정리뷰와 부정리뷰를 구분하는 감성분석을 해보자.
- 긍정/부정 리뷰에서 자주 사용되는 단어를 확인해보자.
2. 데이터 수집
from sklearn.datasets import load_files
train_data = './data/aclImdb/train/'
r_train = load_files(train_data, shuffle=True) #shuffle=True로 섞어서 가져온다.
test_data = './data/aclImdb/test/'
r_test = load_files(test_data, shuffle=True) #shuffle=True로 섞어서 가져온다
r_train.keys()dict_keys(['data', 'filenames', 'target_names', 'target', 'DESCR'])len(r_train.data) #데이터
25000r_train.target #답
array([1, 0, 1, ..., 0, 0, 0])r_train.target_names #0:neg 부정 1: pos 긍정
['neg', 'pos']3. 데이터 전처리
- 텍스트 데이터
- 오탈자 제거
- 띄어쓰기 교정
- 이모티콘 수정
- 불필요한 글자 제거
- 데이터 정형화 : 토큰화, 수치화
r_train.data[0] # bytes형 1bytes 단위의 값을 저장하는 타입
a = [ i for i in range(5)]
a #0~4까지 a에 append 되는 형식
[0, 1, 2, 3, 4]# br태그 제거
# replace("a",1) 기존에 a를 1로 바꿀때는 이렇게 썼는데
#replace(b"a",1) bytes형은 앞에 b를 써야한다
text_train = [ i.replace(b"<br />", b" ") for i in r_train.data]
# r_train.data가 for문안의 i로 들어오고 그게 i.replace(b"<br />", b" ")로 들어온다
len(text_train)
25000.text_train[0] # <br />태그가 다 사라짐
text_test = [ i.replace(b"<br />", b" ") for i in r_test.data]

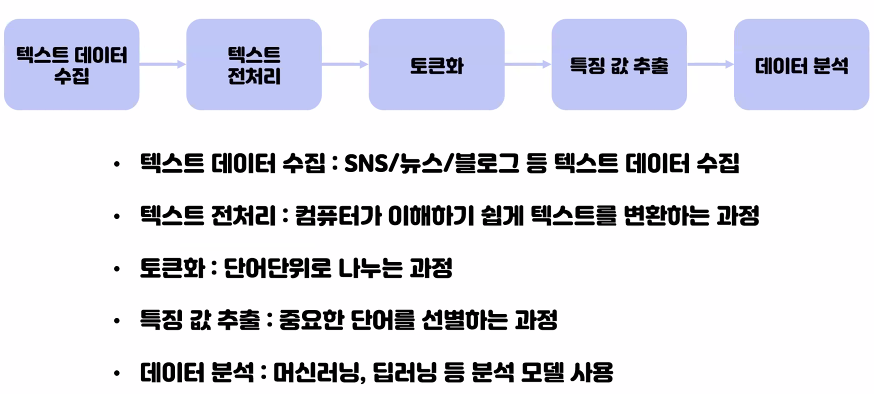
텍스트 수집

텍스트 전처리

토큰화





특징 값 추출

BOW(Bag of word)
from sklearn.feature_extraction.text import CountVectorizer
corpus =['you know I want your love. because I love you.']
vector = CountVectorizer()
print('bag of words vector:', vector.fit_transform(corpus).toarray())
# 각 단어의 인덱스가 어떻게 부여되었는지 출력
print('vocabulary :', vector.vocabulary_)
# 알파벳 I는 BOW 과정에서 사라졌는데, 이는 CountVectorizer가 기본적으로 길이가
# 2이상인 문자에 대해서만 토큰으로 인식하기 때문bag of words vector: [[1 1 2 1 2 1]]
vocabulary : {'you': 4, 'know': 1, 'want': 3, 'your': 5, 'love': 2, 'because': 0}movie_c = CountVectorizer()
movie_c.fit(text_train) #위에는 fit과 transform을 한번에하고 이건 두번에 걸쳐서
len(movie_c.vocabulary_)
74849movie_c.vocabulary_
{'zero': 74609,
'day': 16697,
'leads': 38088,
'you': 74324,
'to': 67125,
'think': 66526,
'even': 22718,
're': 53749,
'why': 72965,
................수치데이터로 변경
X_train = movie_c.transform(text_train)
len(X_train.toarray()[0])
74849X_test = movie_c.transform(text_test)
모델 선택 및 학습
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score #교차검증시 사용
logi = LogisticRegression()
result = cross_val_score(logi, X_train, r_train.target, cv=3)
result
array([0.87736981, 0.87699508, 0.87807512])pipe line
from sklearn.pipeline import make_pipeline
# 수치데이터로 변경후 모델선택후 학습까지 한번에 pipeline을 통해서 진행
pipe = make_pipeline(CountVectorizer(), LogisticRegression())
pipe.fit(text_train, r_train.target)
pipe.steps
[('countvectorizer', CountVectorizer()),
('logisticregression', LogisticRegression())]pipe.steps[1][1].coef_.shape
(1, 74849)pipe.steps[0][1].vocabulary_
{'zero': 74609,
'day': 16697,
'leads': 38088,
'you': 74324,
'to': 67125,
'think': 66526,
..................그리드서치
from sklearn.model_selection import GridSearchCV
#pipeline을 그리드서치 할때 파라미터 앞에 매핑을 해야한다. ex) countvectorizer__
param = {
'countvectorizer__max_df' : [15000, 20000, 23000], #문서에 등장하는 최대빈도수
'countvectorizer__min_df' : [3, 5, 7], #문서에 등장하는 최소빈도수
'countvectorizer__ngram_range' : [(1,1),(1,2), (1,3)], #단어(1,2,3)개를 토큰1개로
#단어 몇개로 토큰화 진행할것인지
'logisticregression__C' : [0.01, 0.1, 1, 10, 100]
}
grid = GridSearchCV(pipe, param, cv=3)
grid.fit(text_train,r_train.target)
grid.best_params_
{'countvectorizer__max_df': 15000,
'countvectorizer__min_df': 3,
'countvectorizer__ngram_range': (1, 3),
'logisticregression__C': 0.1}grid.best_score_
0.8932001916505746
모델활용
review = ['3d ago Make a Prayer Request for marriage stability to SANGOMA Abia a very powerful female herbalist & The Best Traditional doctor who helps solve marriage problems helps job seekers and those in need of a promotion at work. Female Sangoma Abia has strong intercessory power. She has a strong love portion for those who need to fix any kind of relationship problems, Marriage spells for you to stabilize your marriage and for those who need to get married to their soulmate, Stop Cheating Lovers, luck in both lotto and business, and spiritual help for the people who are struggling with job issues. CALL/WHATSAPP SANGOMA ABIA +27614891960 Individual Psychotherapy Couples Counselling Marriage Counselling Pre-Marital Counselling Adolescent Psychotherapy & Teen Counselling Adult Psychotherapy and Counselling Trauma Counselling Christian Counselling Parental Guidance Family Psychotherapy Pastor Support Spiritual Mentoring for individuals and those in ministry. Call/Whatsapp SANGOMA ABIA +27614891960']
movie_c.fit(text_train)
t_review = movie_c.transform(review)
logi = LogisticRegression(C =0.1)
logi.fit(X_train, r_train.target)
logi.predict(t_review)array([1])모델평가
best_model = make_pipeline(CountVectorizer(max_df = 15000,
min_df = 3,
ngram_range=(1,3)), LogisticRegression( C= 0.1)
)
기존의 문장을 토큰화 시킨다 -> 명사, 형태소 등등으로
이 토큰화에서 CountVectorizer 사용 -> 수치형으로 transform해서 pipeline에 fit
'빅데이터 서비스 교육 > 머신러닝' 카테고리의 다른 글
| 네이버 영화 리뷰데이터(konlpy활용) 실습 (0) | 2022.07.07 |
|---|---|
| 앙상블 모델 (0) | 2022.07.05 |
| Linear Model 실습 (0) | 2022.07.01 |
| Linear Model (0) | 2022.06.29 |
| 예제 타이타닉 생존자 예측분석 (0) | 2022.06.24 |