반응형
기존에는 행과 열로 이루어진 table형태의 데이터를 썼다.
특성은 table의 열의 개수 였다.
이미지 데이터는 픽셀하나하나가 특성
-> 1920 X 1080 해상도의 이미지가 약 2,000,000개의 특성의 개수를 가진다
딥러닝 손글씨 이미지 데이터 분류
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# keras에서 지원하는 딥러닝 학습용 손글씨 데이터셋 임프토(국립표준기술원(NIST)의 데이터셋을 수정(Modified)해서 만든 데이터 셋)
from tensorflow.keras.datasets import mnist
data = mnist.load_data()
data
((array([[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
................................................
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]], dtype=uint8),
array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)),
(array([[[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]]], dtype=uint8),
array([7, 2, 1, ..., 4, 5, 6], dtype=uint8)))연산을 위해 array (배열) 형태를 쓴다
len(data)
# 데이터가 3차원 배열로 크기는 train, test로 나뉘어져 있고
# 각 train, test 안에 문제와 정답 데이터로 한 번 더 나뉘어져 있는 구조
2

다음과 같은 형태로 들어있고 그래서 len이 2가 나온다.
print(len(data[0])) # train
print(len(data[1])) # test
print(len(data[0][0])) # X_train
print(len(data[0][1])) # y_train
print(len(data[1][0])) # X_test
print(len(data[1][1])) # y_test
2
2
60000
60000
10000
10000X_train = data[0][0]
y_train = data[0][1]
X_test = data[1][0]
y_test = data[1][1]
# 이미지라는 2차원 데이터를 다루기 때문에 shape의 형태는 3칸이 나오게 됨
# (데이터의 수, 가로픽셀 수, 세로픽셀 수)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
(60000, 28, 28) 첫28 가로픽셀 수 / 28 세로 픽셀수
(60000,)
(10000, 28, 28)
(10000,)y_train
array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)plt.imshow(X_train[59999], cmap='gray');
# imshow : 이미지 데이터를 그림으로 출력해주는 명령
# cmap='gray' : 이미지를 흑백으로 출력시켜주는 명령
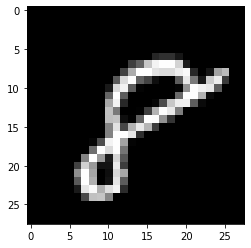
y_train의 마지막인 답8이
X_train 마지막에서 나왔다

8이라는 숫자 출력을 위해
각 픽셀에 숫자들이 들어간다
픽셀에 들어간 숫자는
색상을 뜻한다
0: 검은색 등등
2의8승 : 0~255사이의 숫자
# subplots : 여러개의 그래프를 하나의 공간에 표시해주는 함수
# f : 전체 그래프를 조절하는 변수
# axes : 내부 그래프를 조절하는 변수
f, axes = plt.subplots(2,2) #가로2개, 세로2개씩 내부 그래프를 표시
# 전체 그래프의 사이즈 설정
f.set_size_inches(8,8)
# 인덱싱으로 내부 그래프에 접근
axes[0][0].imshow(X_train[59999], cmap='gray')
axes[0][1].imshow(X_train[59998], cmap='gray')
axes[1][0].imshow(X_train[59997], cmap='gray')
axes[1][1].imshow(X_train[59996], cmap='gray')
plt.show()
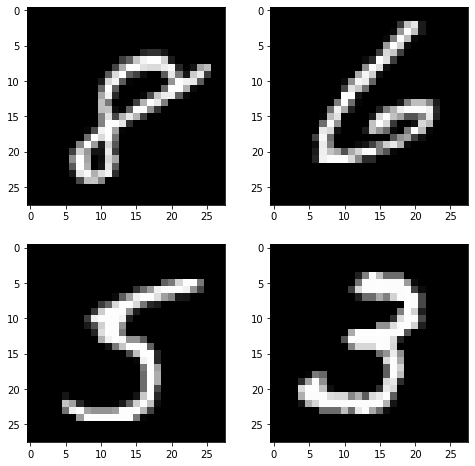
다중분류 문제에는 정답 데이터를 원핫인코딩 해야 한다
- pd.get_dummies : pandas에서 지원해주는 원핫인코딩 명령
- to_categorical : keras에서 지원해주는 원핫인코딩 명령
from tensorflow.keras.utils import to_categorical
y_train_one_hot = to_categorical(y_train)
y_test_one_hot = to_categorical(y_test)
y_train_one_hot
array([[0., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.]], dtype=float32)y_train.shape, y_train_one_hot.shape
((60000,), (60000, 10))
신경망에 데이터를 넣을때 2차원데이터를 1차원으로 쭉 이어서 1차원으로 넣어야 한다.
28 X 28의 2차원데이터를 1차원으로 쭉이어서 넣고
이때의 특성의 개수는 28X28 개
- 신경망에는 2차원인 이미지데이터를 한 번에 넣을 수가 없기 때문에 데이터의 차원을 1차원으로 변경시켜줘야 한다
X_test.shape
(10000, 28, 28)# -1의 의미: 60000을 제외한 나머지 값들을 전부 곱해서 일렬로 펴줌
X_train = X_train.reshape(60000, -1)
X_test = X_test.reshape(10000, -1)
X_test.shape
(10000, 784)
# -1을 써서 28,28을 1차원 784로 펴줬다신경망 구조를 직접 설계 해보자
- 입력되는 특성 수
- 출력층 활성화함수
- 손실함수(loss)
- 최적화함수
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
# 입력되는 특성수 = 특성개수
model.add(Dense(100, input_dim=784, activation="relu"))
model.add(Dense(50, activation="relu"))
model.add(Dense(30, activation="relu"))
model.add(Dense(15, activation="relu"))
# 출력층 뉴런의 개수 = 정답의 수
model.add(Dense(10, activation="softmax"))
model.compile(loss="categorical_crossentropy",
optimizer="Adam",
metrics=['acc'])
h = model.fit(X_train,y_train_one_hot, epochs=30, verbose=1)
# verbose : 학습 결과의 출력 형태를 설정하는 명령(0:출력X, 1:bar형태(기본값), 2:bar가 없는 형태)
Epoch 1/30
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0337 - acc: 0.9912
Epoch 2/30
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0296 - acc: 0.9919
Epoch 3/30
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0281 - acc: 0.9925
Epoch 4/30
.....................................................................................
Epoch 29/30
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0159 - acc: 0.9960
Epoch 30/30
1875/1875 [==============================] - 6s 3ms/step - loss: 0.0188 - acc: 0.9954plt.figure(figsize=(15,5))
plt.plot(h.history['acc'], label=['acc'])
plt.legend()
plt.show()
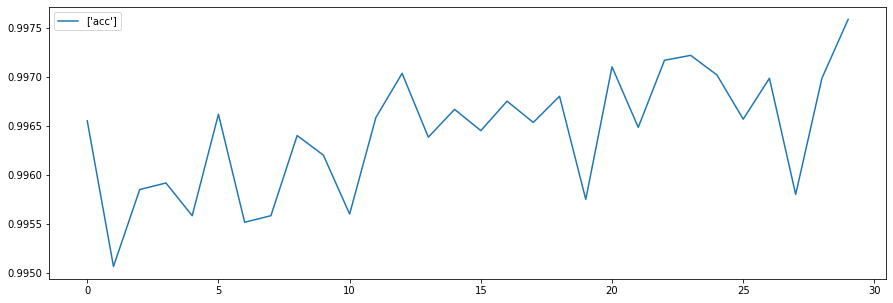
학습을 시킬때 검증용 데이터를 넣어서 epoch마다 학습데이터에 들어있지 않은 검증용데이터로
모델이 과대적합, 과소적합이 되고 있지않은지 학습 중에 알 수 있다.
학습중 과대적합을 확인하기 위해 train데이터에서 검증데이터셋을 분리해서 학습시 같이 출력해보자
from sklearn.model_selection import train_test_split
X_train, X_val, y_train_one_hot, y_val_one_hot = train_test_split(X_train,
y_train_one_hot,
random_state=3)
print(X_train.shape)
print(X_val.shape)
print(y_train_one_hot.shape)
print(y_val_one_hot.shape)
(45000, 784)
(15000, 784)
(45000, 10)
(15000, 10)model1 = Sequential()
# 입력되는 특성수 = 특성개수
model1.add(Dense(500, input_dim=784, activation="relu"))
model1.add(Dense(300, activation="relu"))
model1.add(Dense(500, activation="relu"))
# 출력층 뉴런의 개수 = 정답의 수
model1.add(Dense(10, activation="softmax"))
model1.compile(loss="categorical_crossentropy",
optimizer="Adam",
metrics=['acc'])
h1 = model1.fit(X_train,y_train_one_hot, epochs=30, verbose=1,
validation_data=(X_val, y_val_one_hot))
Epoch 1/30
1407/1407 [==============================] - 7s 4ms/step - loss: 1.0702 - acc: 0.8887 - val_loss: 0.3112 - val_acc: 0.9266
Epoch 2/30
1407/1407 [==============================] - 6s 4ms/step - loss: 0.2263 - acc: 0.9413 - val_loss: 0.2069 - val_acc: 0.9461
................................................................................................
Epoch 29/30
1407/1407 [==============================] - 5s 4ms/step - loss: 0.0439 - acc: 0.9916 - val_loss: 0.2723 - val_acc: 0.9696
Epoch 30/30
1407/1407 [==============================] - 6s 4ms/step - loss: 0.0403 - acc: 0.9926 - val_loss: 0.3177 - val_acc: 0.9640학습용과 검증용 데이터의 정확도가 둘 다 나와서 둘의 차이를 보고 학습이 잘 되는지 알수 있다.
plt.figure(figsize=(15,5))
# train 데이터
plt.plot(h1.history['acc'], label=['acc'],
c='blue', marker='.')
# val 데이터
plt.plot(h1.history['val_acc'], label=['val_acc'],
c='red', marker='.')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show()
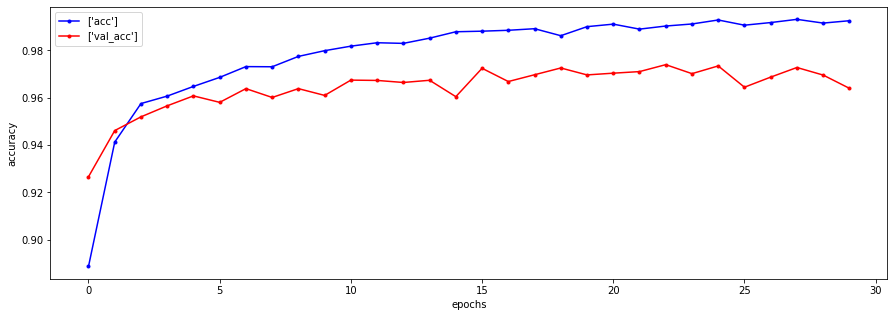
epoch10이상부터 검증데이터랑 확인데이터랑 약 2%차이가 난다
-> 45000개중 2% 90개정도의 손글씨의 답 오차가 있는데 이 경우에는 괜찮은데,
하지만 틀리면 안되는 데이터로 평가 할때는 2%오차도 크다
pre = model1.predict(X_test)
pre
array([[0.0000000e+00, 1.8751669e-20, 4.7428191e-25, ..., 1.0000000e+00,
0.0000000e+00, 4.5607094e-24],
[0.0000000e+00, 0.0000000e+00, 1.0000000e+00, ..., 0.0000000e+00,
0.0000000e+00, 0.0000000e+00],
[0.0000000e+00, 1.0000000e+00, 0.0000000e+00, ..., 0.0000000e+00,
0.0000000e+00, 0.0000000e+00],
...,
[0.0000000e+00, 1.5019263e-25, 0.0000000e+00, ..., 4.5958856e-23,
0.0000000e+00, 6.5949099e-17],
[3.6372215e-18, 8.1131090e-26, 0.0000000e+00, ..., 0.0000000e+00,
2.0007450e-30, 4.8949159e-20],
[3.4164470e-19, 0.0000000e+00, 3.1683486e-28, ..., 0.0000000e+00,
4.7570816e-16, 0.0000000e+00]], dtype=float32)pre[0]
array([0.0000000e+00, 1.8751669e-20, 4.7428191e-25, 3.7090377e-29,
4.6419196e-33, 0.0000000e+00, 0.0000000e+00, 1.0000000e+00, # 7번이 1로 100%확률
0.0000000e+00, 4.5607094e-24], dtype=float32)y_test_one_hot[0]
array([0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], dtype=float32) # 실제 정답도 7번이 정답
model1.evaluate(X_test, y_test_one_hot)
313/313 [==============================] - 1s 3ms/step - loss: 0.2485 - acc: 0.9677
[0.24846406280994415, 0.9677000045776367]
from tensorflow.keras.layers import Dense, Flatten
# Flatten : 데이터를 1차원으로 자동적으로 펴주는 역할을 하는 모듈
model = Sequential()
model.add(Flatten(input_shape=(28,28))) # 입력층에 특성개수 따로 입력 안해도 된다.
model.add(Dense(500, activation="relu"))
model.add(Dense(300, activation="relu"))
model.add(Dense(100, activation="relu"))
model.add(Dense(10, activation="softmax"))
h = model.fit(X_train, y_train_one_hot, epochs=30, verbose=1,
validation_data=(X_val, y_val_one_hot),
batch_size=128) # batch_size : 연산 한 번에 들어가는 데이터의 크기

- 손글씨와 패션이미지의 데이터 수, Dense등은 거의 같았는데 정확도가 패션이미지 데이터에서 더 낮을 이유는 데이터의 차이이다. -> 손글씨 이미지는 알아보기 쉬웠고 패션이미지는 알아보기 힘든 데이터 였다.
반응형
'빅데이터 서비스 교육 > 딥러닝' 카테고리의 다른 글
| 활성화함수, 최적화 함수 (0) | 2022.07.19 |
|---|---|
| 사람 얼굴 이진분류 모델 생성 (0) | 2022.07.19 |
| 딥러닝 iris 데이터 신경망으로 풀기 (다중 분류) (0) | 2022.07.14 |
| 활성화함수 (0) | 2022.07.14 |
| 딥러닝 유방암 데이터 분류 예제 (0) | 2022.07.14 |